
Source: Image by Jema stock on Freepik
Introduction
In today’s data-driven world, businesses generate and store an enormous amount of data every day. Data is the backbone of every business and is critical to making informed decisions.
However, as the data grows, the database management systems are subjected to a significant amount of load, leading to the system’s slow down or even crashing.
Load balancing is an effective technique that can help distribute the load across multiple servers, ensuring that the database can handle the increased demand without slowing down or crashing.
In this blog post, we will explore the concept of load balancing in database management systems, its importance, and its various aspects.
What is Load Balancing?
Source: Image by Grommik on Freepik
Load balancing is a technique that distributes the workload across multiple servers to prevent any one server from being overloaded. In a database management system, load balancing can be achieved by distributing the queries across multiple servers.
This approach ensures that each server handles only a fraction of the total workload, resulting in improved performance, scalability, and availability.
Load balancing is essential for ensuring that a database management system can handle high volumes of data with ease.
By distributing the workload across multiple servers, load balancing ensures that the system can handle the increased demand without slowing down or crashing, providing uninterrupted access to the data.
Types of Load Balancing
There are two types of load balancing techniques: hardware-based and software-based.
Hardware-based load balancers are custom-designed physical devices installed between the security system and the server infrastructure. They are known for their high throughput, low latency, and advanced features such as SSL (Secure Sockets Layer) offloading and DDoS (distributed denial of service) protection.
Software-based load balancers are virtual appliances that run on standard hardware, installed on servers or in virtual machines. They are known for their flexibility and ease of deployment on existing infrastructure, making them a cost-effective choice that can be easily scaled up or down depending on demand.
The choice between hardware-based and software-based load balancers depends on the specific needs of the organization and its IT infrastructure.
Hardware-based load balancers are ideal for high-performance and high-budget environments, while software-based load balancers are a better choice for smaller or more dynamic environments.
Load Balancing Algorithms

Source: Image by Starline on Freepik
Load balancing algorithms determine how the workload is distributed across servers.
There are several load balancing algorithms available, including round-robin, least connections, IP hash, and weighted round-robin:
1. Round Robin: Requests are distributed across the group of servers sequentially.
2. Least Connections: A new request is sent to the server with the fewest current connections to clients. The relative computing capacity of each server is factored into determining which one has the least connections.
3. Least Time: Sends requests to the server selected by a formula that combines the fastest response time and fewest active connections. This algorithm is exclusive to NGINX Plus.
4. Hash: Distributes requests based on a key you define, such as the client IP address or the request URL. NGINX Plus can optionally apply a consistent hash to minimize redistribution of loads if the set of upstream servers’ changes.
5. IP Hash: The IP address of the client is used to determine which server receives the request.
6. Random with Two Choices: Picks two servers at random and sends the request to the one that is selected by then applying the Least Connections algorithm (or for NGINX Plus, the Least Time algorithm if configured to do so).
Benefits of Load Balancing
Load balancing provides several benefits to organizations, including:
- Improved System Performance
- Scalability
- Availability
By distributing the workload across multiple servers, load balancing ensures that the system can handle the increased demand without slowing down or crashing. This provides uninterrupted access to the data, improving the overall user experience.
Load balancing also makes it possible for organizations to scale their systems as their data grows.
By adding more servers to the system, organizations can distribute the workload across multiple servers, ensuring that the system can handle the increased demand without slowing down or crashing.
Cloning And Its Importance in Load Balancing Configuration for High Availability

Source: Image by GarryKillian on Freepik
Cloning is the process of creating an exact copy of a server or database instance.
In the context of load balancing, cloning is important for achieving high availability. By cloning servers, an organization can ensure that there are multiple instances of the database available to handle the workload.
If one server fails, the cloned server can take over, ensuring that the system remains available and accessible to users.
Cloning can be achieved through various methods, including physical cloning and virtual cloning.
Physical Cloning Vs Virtual Cloning
Physical cloning involves creating a copy of the server using physical hardware, while virtual cloning involves creating a copy of the server using virtualization technology.
Cloning is an essential part of load balancing configuration for high availability. By ensuring that there are multiple instances of the database available to handle the workload, organizations can ensure that their critical data is always available and accessible to their users.
This improves the overall user experience and ensures that the organization can meet its data needs, no matter how large the workload.
Software Load Balancers vs Hardware Load Balancers: Which is Better for Your DB System?

Source: Image by rawpixel.com on freepik
When it comes to load balancing in database management systems, there are two types of load balancing techniques: software-based and hardware-based.
Both techniques have their pros and cons, and choosing the right one for your organization depends on your specific needs and workload requirements.
Software-Based Load Balancers
Software-based load balancers involve using software to distribute the workload across servers.
Using software is more flexible and cost-effective than hardware-based load balancing but may not offer the same level of performance.
Software-based load balancers are ideal for smaller or dynamic organizations that do not have the budget or for larger organizations.
They are also suitable for organizations that need to balance the workload across cloud-based servers.
Hardware-Based Load Balancers
Hardware-based load balancers involve using a dedicated hardware device to distribute the workload across servers.
Hardware is more expensive than software-based load balancing but offers better performance and scalability.
Hardware-based load balancers are ideal for organizations that handle big data and require high performance and scalability.
They are also suitable for organizations that need to balance the workload across on-premises servers.
Which is Better?
The choice between software-based and hardware-based load balancing depends on your organization’s specific needs and workload requirements.
If you are a smaller organization with a limited budget and workload, a software-based load balancer may be the best option for you.
If you are a larger organization with a high workload and need for performance and scalability, a hardware-based load balancer may be the best option.
It is important to consider the total cost of ownership, including maintenance and support, when choosing between software-based and hardware-based load balancing.
Additionally, it is important to consider your organization’s future growth and scalability needs when making the decision.
A Closer Look at Clustering in DB Systems: Standard Vs Enterprise Clustering
Clustering is a technique used in database management systems to improve availability and performance by grouping multiple servers together.
Standard clustering involves grouping servers together for failover purposes, while enterprise clustering involves grouping servers together for performance and scalability.
Advantages And Disadvantages of Standard and Enterprise Clustering
The advantages of standard clustering include improved availability and failover capabilities, while the advantages of enterprise clustering include improved performance and scalability.
The disadvantages of standard clustering include limited scalability and performance, while the disadvantages of enterprise clustering include increased complexity and cost.
Best Practices for Implementing and Managing Load Balancers

Source: Image by rawpixel.com on Freepik
Implementing and managing load balancers in database management systems requires careful planning and execution.
Here are some best practices to ensure that load balancers are implemented and managed effectively:
- Define Your Goals
Before implementing load balancers in your database management system, define your goals.
Determine what you want to achieve with the load balancer, such as improved system performance, scalability, and availability. This will help you choose the right load balancing technique and algorithm for your needs.
- Choose the Right Load Balancing Technique
Choose the right load balancing technique for your needs. Hardware-based load balancing is ideal for organizations that handle substantial amounts of data and require exceptional performance and scalability.
In contrast, software-based load balancing is suitable for smaller organizations that do not require the same level of performance and scalability as larger organizations.
- Choose the Right Load Balancing Algorithm
Choosing the right load balancing algorithm is crucial for optimal system performance. Consider your specific needs and workload requirements when selecting a load balancing algorithm.
For example, if your organization handles many requests from a single IP address, then IP hash may be the best algorithm to use.
- Monitor Your System
Monitor your system to ensure that load balancers are working effectively.
Regularly check system performance metrics, such as response time and server utilization, to identify any issues that may be impacting system performance.
- Test Your Load Balancers
Test your load balancers to ensure that they are working effectively.
Use load testing tools to simulate high loads and identify any performance issues that may need to be addressed.
- Implement Redundancy
Implement redundancy to ensure that load balancers do not become a single point of failure.
Use multiple load balancers and configure them in a failover configuration to ensure the system can continue operating in case of a failure.
By following the above best practices, organizations can ensure that their load balancers are implemented and managed effectively, improving system performance, scalability, and availability.
Troubleshooting Common Issues with Load Balancers and Clustering in DB Systems
Source: Image by Storyset on Freepik
Load balancers and clustering are essential components of database management systems, but they are not without their challenges.
Here are some common issues that organizations may encounter when implementing load balancers and clustering, along with some troubleshooting tips:
- Network Latency
Network latency can be a significant issue in load balancing and clustering.
Latency occurs when there is a delay in data transmission between servers, which can lead to slow performance and decreased system availability.
To troubleshoot network latency issues, organizations should:
- Optimize network settings to reduce latency
- Use caching and compression to reduce data transmission times
- Use a high-speed, low-latency network connection
- Database Inconsistencies
Load balancing and clustering can sometimes cause database inconsistencies, where data on one server is not synchronized with data on another server.
This can lead to incorrect or inconsistent results, which can impact system performance and user experience.
To troubleshoot database inconsistencies, organizations should:
- Use a database replication solution to keep data coordinated across servers
- Implement a failover mechanism to ensure that the system can continue to operate in the event of a failure
- Monitor the system for inconsistencies and address them as soon as possible
- System Overload
Load balancing and clustering can also cause system overload, where the system is unable to handle the workload and crashes.
This can occur when the workload is too high or when the load balancer or clustering software is not configured correctly.
To troubleshoot system overload issues, organizations should:
- Monitor system performance metrics, such as response time and server utilization, to identify any issues that may be impacting system performance
- Use load testing tools to simulate high loads and identify any performance issues that may need to be addressed
- Configure load balancing and clustering software correctly.
Best Practices for Troubleshooting Load Balancers and Clustering in DB Systems
- Monitor system performance metrics, such as response time and server utilization, to identify any issues that may be impacting system performance
- Use load testing tools to simulate high loads and identify any performance issues that may need to be addressed
- Use a database replication solution to keep data coordinated across servers and prevent database inconsistencies
- Implement a failover mechanism to ensure that the system can continue to operate in the event of a failure
- Optimize network settings to reduce latency and improve system performance
- Configure load balancing and clustering software correctly to prevent system overload and other performance issues
Why Work With us
We are a software-based load balancer provider, and we are passionate about helping businesses improve their website and application performance.
Load balancing is a critical component of any modern IT infrastructure, as it ensures that web traffic is distributed evenly across multiple servers. This not only prevents downtime and ensures high availability, but it also improves website speed and user experience.
At Finsense Africa, we pride ourselves on providing reliable, efficient, and cost-effective load balancing solutions to businesses of all sizes.
Our team of experts is dedicated to helping you improve your system performance, so you can focus on growing your business. Contact us today to learn more about our services and how we can help you.
Sources
- What is Load Balancing?
Summary
The article talks about load balancing in database management systems. The system becomes slow or crashes when subjected to a significant amount of load, which is prevented by load balancing.
Load balancing distributes the workload across multiple servers, resulting in improved performance, scalability, and availability. There are two types of load balancing techniques – hardware-based and software-based.
Load balancing algorithms such as round-robin, least connections, IP hash, and weighted round-robin are available. Load balancing provides several benefits, including improved system performance, scalability, and availability.
Cloning is the process of creating an exact copy of a server or database instance and is essential for high availability. Physical cloning and virtual cloning are two methods of cloning.
Choosing the right type of load balancer for an organization depends on its specific needs and workload requirements.
]]>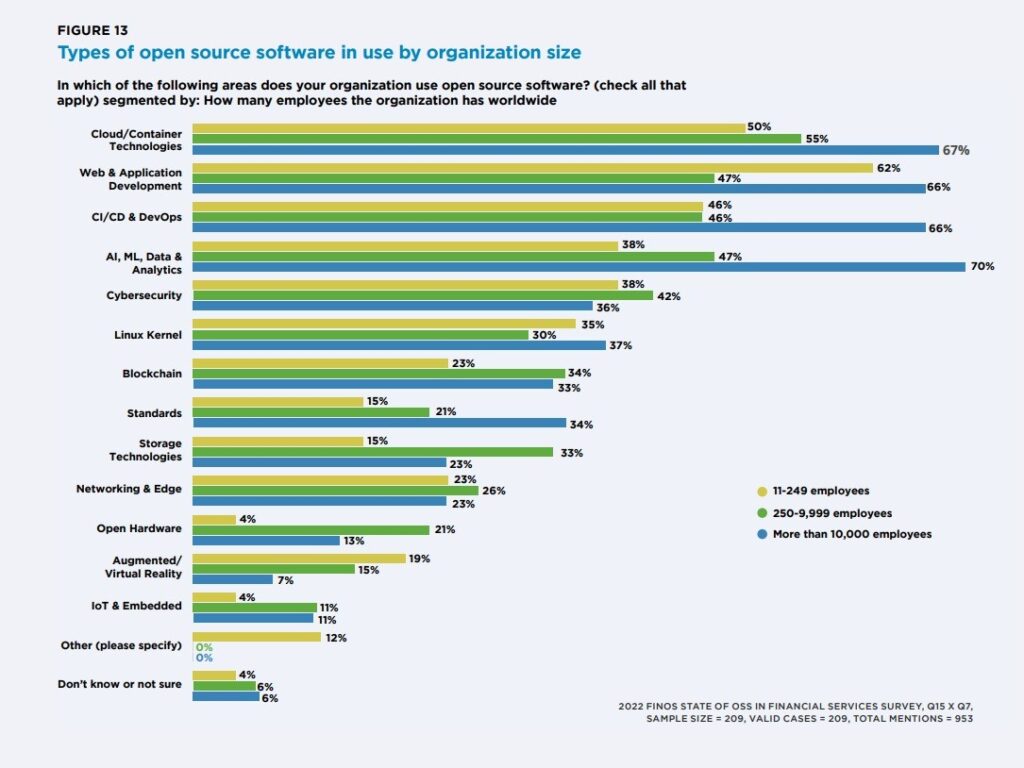
Top organizations use open source they include Google, Facebook, Microsoft, Amazon, IBM, Twitter, Red Hat, Uber, Airbnb, and Netflix.
Why are banks and hedge funds suddenly into open source. Past practices have indicated that banks are very competitive and cautious of their proprietary data.
Since they handle confidential data, they’ve been expected to keep secrets. For example, in 2009 Goldman Sachs had an employee jailed for allegedly stealing their proprietary software.
However, 8 years later in 2017 Goldman Sachs launched three of its latest open-source projects – Jrpip, Obevo and Tablasco – on GitHub. They also have an in-house language, Legend, that is now open source.
In the creation and use of open-source tech-based companies outperform financial businesses. For instance, Google has 70 open-source projects. The largest of them all is Android which is 75% of what all smart phones use.
Why Organizations Choose Open-Source
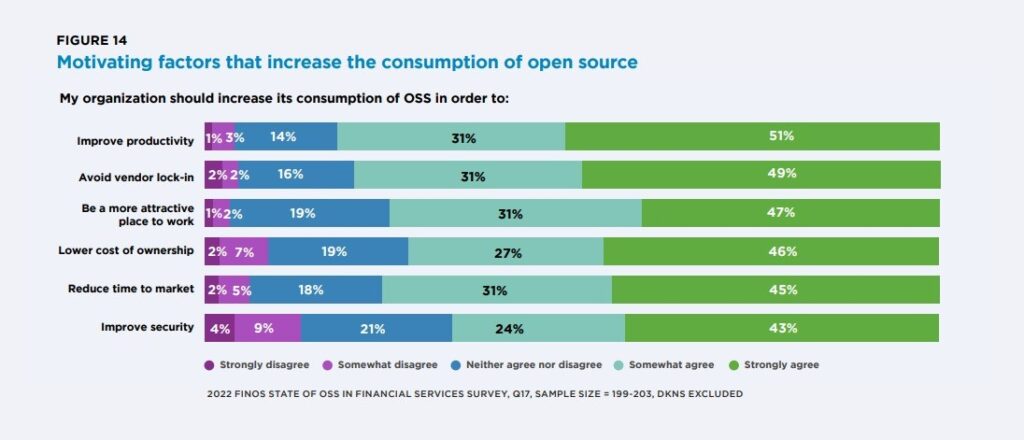
As a result, banks in 2023 will increasingly adopt open-source technology, as they are under pressure to innovate and remain competitive. This shift is driven by a desire to gain access to new and emerging technologies, such as machine learning and blockchain, to improve customer experience and reduce operating costs.
Banks are opting for open-source technology because
- Cost Savings: Open source saves costs by eliminating the need to pay for expensive proprietary software licenses and reducing development costs by leveraging existing open-source solutions.
- Customization: It can be customized to fit an organization’s unique needs, as opposed to proprietary software which may be more rigid.
- Security: Is more secure because vulnerabilities can be quickly identified and addressed by the community of developers.
- Innovation: Foster innovation by allowing organizations to collaborate and share ideas with others in the community.
- Reliability: Open source has proven to be reliable and stable in mission-critical applications. For example, the Linux operating system is widely used in mission-critical applications such as space missions and stock exchanges.
- Community Support: Open-source communities can guide and assist organizations with their projects, including bug fixes and development advice. The Apache web server project is an example of a project that benefits from a large and active developer community for ongoing support
- Future Outlook: More organizations are likely to adopt open-source solutions, like Red Hat Enterprise Linux, which provides a secure and stable operating system that can be tailored to meet specific business needs.
In addition, open-source software is flexible to customize to specific needs. This allows banks to develop innovative applications that leverage the latest technologies, such as AI and machine learning, to understand customer behavior and anticipate their financial needs.
Real-Life examples of Open-Source Technology Adoption
One example of open-source technology being adopted by banks is the operating system Linux. Banks such as ING, UBS and JPMorgan Chase have implemented Linux powered systems to better manage their IT infrastructure. They use it to:
- Host their IT infrastructure and provide a secure computing environment.
- Develop custom applications, such as mobile banking and digital wallets.
Other open-source projects that are popular in the banking sector include:
- Apache Kafka, an event streaming platform
- Hadoop, a big data analytics platform
Historically banks have been hesitant to adopt open-source software; where software source code is shared and made freely available). With traditional vendors like IBM, TIBCO, Oracle strongly positioned in this industry, the move to open source has been slow.
In recent years, forced by a rapidly changing business, banks are transforming their IT organizations considerably, adopting new technologies and methodologies like Cloud, microservices, Open APIs, DevOps, Agile and Open Source. Because often the above adoptions enforce each other.
The Open-Source movement has reached maturity. While 5-10 years ago, it was associated with computer-nerds, idealists and small start-ups, today it is mainstream. The recent acquisitions of open-source companies by large established corporate tech-vendors is the best proof of this evolution:
- SalesForce bought MuleSoft for $6.5 billion in March 2018
- Microsoft bought GitHub for $7.5 billion in October 2018.
- IBM purchased Red Hat for $34 billion in 2019
At the same time these incumbent tech players are adopting open-source strategies themselves. For example, Microsoft, initially one of the most guarded, has adopted an open-source strategy, since Satya Nadella became CEO in 2014. Examples of its open-source technologies include:
- Edge: The Edge browser is switching to the Google based open-source chromium platform
- .NET framework: the full .NET framework was open-sourced on Git-Hub
- Windows 10: built on open-source Progressive Web App technology
- Windows 11: analysts speculate that the NT kernel would be (gradually) replaced by the Linux kernel
- Azure platform: the most used operating system on Microsoft Azure is not Windows Server, but rather Linux
- Open-source contribution: Microsoft has become the largest contributor to open source in the world. It is more active than the second most active contributor, Google. There are 20,000 Microsoft employees on GitHub and over 2,000 open-source projects
The Different Stages of Open-Source Adoption
Open-source software has many benefits for banks, but it requires a cultural shift in the whole organization, which takes time and intensive change management.
Banks can start adopting open-source software in different ways. They can start by using open-source software where possible, either as full solutions or as components they combine to build custom applications.
As they become more familiar with open-source software, banks can start contributing back to the community by identifying bugs and implementing valuable features. By doing so, banks improve their corporate image and benefit from future testing and extensions by the community.
The final step is to open the bank’s existing proprietary software, which is the most complex and time intensive.
First, banks fear their code will be scrutinized in public, resulting in a brand risk and potentially exposing security issues. Additionally, some bank leaders may fear giving away competitive advantage.
Second, depending on the kind of open-source software. How complex is it? Banks should first gain experience with low-level abstraction open-source software, like:
- Databases (MySQL, Mongo DB, Cassandra and Postgres),
- Middleware (WSO2, Kafka, Apache Camel, Envoy, Istio)
- Operating systems (Linux and Kubernetes)
Gradually they can move up the stack to higher level of abstractions, like:
- Business process (jBPM)
- Task management tools
Finally, they can use also open source for the financial core processes. These include, Cyclos, Mifos X / Apache Fineract, MyBanco, Jainam Software, OpenCBS, OpenBankProject, Cobis, OpenBankIT, Mojaloop).
Contributing to Open-Source
Ultimately the banks’ software should have at its core open-source software, except for solutions exclusively offered via SaaS.
Many banks already use open-source software and prefer it over proprietary software. More banks are contributing to open-source projects or open-sourcing their own software. Some examples of such banks include:
- Capital One’s, one of the largest credit card companies in the US, has been on a digital transformation journey over the past 6 years.
- Goldman Sachs recently open sourced its proprietary data modeling program Alloy
- J.P. Morgan Chase released code on GitHub for multiple initiatives; its Quorum blockchain project.
- Deutsche Bank open-sourced multiple projects, like Plexus Interop (from its electronic trading platform Autobahn) or Waltz (IT estate management
The Dilemma of Open-Sourcing In-House Software
The move of some banks to open-source proprietary software seems strange at first sight, as intelligent software has become the competitive edge of any bank. Nonetheless banks have a lot to gain in using (adopting) open source and contributing to it:
5 Benefits of using open-source software:
- Lower costs: avoid the exuberant annual software license costs paid to software vendors.
- Reduce time-to-market: allowing developers to bolt together pre-existing modules rather than having to create them all from scratch, allows to considerably reduce development time.
- Easily customizable: open-source software can be customized, allowing to provide the golden means between buying a software package from a vendor (quick time-to-market, but limited customization possibilities) and internally custom-built software.
- No vendor lock-in
- Lower learning curve for new joiner
7 Benefits of Contributing to Open-Source Software:
- Good for corporate image through giving back to the community.
- Transparency: open-source software is intrinsically more secure than proprietary software, where the code is kept a secret.
- Easier hiring of resources, as IT resources like to work on open-source and good potential candidates can be identified by looking at public commits of externals to the bank’s open-source projects
- Motivation: often IT resources at banks feel a lack of social commitment. Contributing back to open sources can give them a feeling of pride and giving back to community.
- Cultural accelerator: open-source communities promote collaboration, almost always remote and often across different time zones and cultures. Collaborating in such an environment will make the bank IT department better and more adapted for future evolutions.
- Gain from testing and extensions built by contributors outside the bank
- Facilitates collaboration between different banks on shared concerns like KYC (Know Your Customer) and AML (Anti-Money Laundering)
5 Fears of Making In-House Software Open-Source
Even though open source has many advantages, there are still some banks that are hesitant to use it. These banks are especially hesitant to contribute to open source or share their own software. Here are some reasons:
- Contractual and legal: Various types of open-source software license models exist which can make it challenging for large banks to comply with all the terms and conditions. But tools like FOSSA, DejaCode, WhiteSource, Code Janitor help monitor and follow-up the compliance on open-source licenses.
- Support: Banks worry about a lack of support when using open-source tools. However, many open-source tools offer corporate support. If not, the bank IT teams should engage with the open-source community to resolve an issue.
- Compliance and security: There are risks when publishing source code on the internet that criminals can find loopholes in the code. While open-sourcing code ultimately leads to more secure software.
- Losing Competitive advantage: Most internal banking software is commodity software that doesn’t provide any differentiation. Open sourcing these applications can free up resources to work on real value-added services.
- Brand risk: Banks are concerned that open-sourcing bad software can harm corporate branding
How Does Open-Source affect FinTech
If banks start using a lot of open-source software, will FinTech’s new software services offer to banks, fail?
Fortunately, fintech has already moved from an annual license model to newer partnership models. Using cloud technology and Open APIs has made it hard to justify annual licenses.
Partnership models are now used instead of software license costs. These include:
- PaaS (Platform as a Service), SaaS (Software as a Service) and Baas (Business as a Service) models
- “Open core” models (also called Dual licensing). Here, the core of the software is delivered for free and open source. However, the tooling for large corporations are license based
- Support model: pay a party for access to a support desk and providing updates on when new versions should be installed
- Service model for profits; training services, implementation services, customizations to the open-source software at request of the banks.
Making an open system of collaboration between FinTech and banks will lead to better services for everyone. Banks should understand that technology is important for their business.
They should learn from the big technology companies by hiring the best people, using existing software, and supporting quick changes with DevOps and Agile methods. Banks can use open-source strategies to achieve this goal.
References:
]]>
The future of finance is changing rapidly. Over the past decade, advanced machine learning has taken over many tasks that humans previously performed.
From self-driving cars to smart phones, these technologies have advanced at an exponential rate. Now, new technologies are emerging that use artificial intelligence (AI) to complement existing processes and provide insights that allow people to make better decisions.
In November 30th 2022 Open AI launched ChatGPT. By December 4th the open platform had over a million users, breaking the records other popular platforms.
Facebook took up to 10 months before accumulation one million users. Twitter took up to 2 years to get to a million users. Last but not least, TikTok, The Open AI innovation received up to 1million users in 24 hours.
The amount of posts on LinkedIn and YouTube about the supposed solution to all repetitive tasks were uncontrollable. Experts have mixed reactions to the possibilities of AI, some agree that it’s impact has been far-reaching and positive so far.
Understanding the impact of AI on finance services
Today, AI is an integral part of our lives. From self-driving cars and video games to Netflix’s recommendation engine and Facebook’s algorithm, AI is no longer just in our pocket (it’s in everything).
But what has this changed for the financial services industry? What are the biggest risks and opportunities that it can bring? And how will AI impact your role in finance moving forward?
According to the mckinsey-tech-trends-outlook-2022-research-overview.pdf Applied AI received $165 billion investment funding in 2022.
Through the machine learning Canonical stack, we are witnessing the democratization of AI. The use of artificial intelligence will aid in the management of credit card fraud risks and the prevention of losses.
The benefits of AI in the financial industry

The benefits of AI in the financial industry are manifold. The technology is expected to reduce the costs of customer service and improve efficiencies across all stages of the process. It will also enable banks to enhance their product offerings and offer tailor-made services to customers.
The introduction of AI technologies is expected to provide financial institutions with a competitive advantage, enabling them to better adapt to the rapidly changing market environment.
AI has been a major buzzword for years now and has become a popular topic of discussion as we aim to reinvent our future. As AI becomes mainstream here are some benefits the financial industry will enjoy:
● Lower costs by automating repetitive tasks that take up a lot of time.
● Improved customer experience through personalized recommendations and personalization.
● Improved efficiency by utilizing machine learning algorithms to make better decisions.
● Increase in revenue through improved market research and analysis.
The financial services industry is undergoing a transition as AI becomes more pervasive. It’s no longer about the mythical replacing humans with machines, but leveraging artificial intelligence to better serve customers and improve operations.
In fact, AI can play a key role in helping banks and other financial institutions create value for their customers and deliver a better customer experience.
Here are some ways AI will improve the customer’s journey:
1. Improving customer service: Analyzing data from transactions and account activity to identify trends that can be used for predictive analytics. For example, AI could analyze historical transaction data and identify trends such as when customers purchase certain products or make payments on time. This allows banks to predict which customers might need assistance in the future.
2. Automating tasks: AI can automate many of the tasks currently done manually, freeing up employees for customer support. For example, an AI system might be able to integrate information from multiple sources, such as account statements, credit scores and social media posts, into a single report that shows the entire picture of your finances in real time.
3. Predicting client behavior: With enough data about customers’ past spending habits, an AI system could predict what they’re likely to want in the future.
4. Decision support systems, which are based on data analysis and machine learning algorithms, can assist in making financial decisions (DSS).
The impact of AI on finance is that it can automate many manual tasks, freeing up time and resources for humans to focus on higher-value activities. These include:
1. Predicting future events, such as the weather or stock prices, which could be used to make better investment decisions.
2. Creating original content, such as articles and videos, which can be shared with customers in order to drive engagement and loyalty.
3. Insights into customers’ behavior and preferences, which will help them understand how best to serve them. AI can analyze large amounts of financial data to forecast future outcomes or trends, a process known as advanced analytics or big data analytics (aka BDaaS).
Predictions for the adoption of AI in 2023
Artificial intelligence (AI) leaders, consultants and vendors looked at enterprise trends and made their predictions. After a whirlwind 2022, here are some quoted highlights of their insights:
1. AI will be at the core of connected ecosystems —–Vinod Bidarkoppa, CTO of Sam’s Club and SVP of Walmart
In 2023, we’re going to see more organizations start to move away from deploying siloed AI and ML applications that replicate human actions for highly specific purposes and begin building more connected ecosystems with AI at their core.
This will enable organizations to take data from throughout the enterprise to strengthen machine learning models across applications. Hence effectively creating learning systems that continually improve outcomes.
For enterprises to be successful, they need to think about AI as a business multiplier, rather than simply an optimizer.
2. AI will create meaningful coaching experiences— Zayd Enam, CEO, Cresta
Modern AI technology is already being used to help managers, coaches and executives with real-time feedback to better interpret inflection, emotion and more, and provide recommendations on how to improve future interactions.
The ability to interpret meaningful resonance as it happens is a level of coaching no human being can provide.
3. AI will empower more efficient DevOps – Kevin Thompson, CEO, Tricentis
When it comes to devops, experts are confident that AI is not going to replace jobs; rather, it will empower developers and testers to work more efficiently. AI integration is augmenting people and empowering exploratory testers to find more bugs and issues upfront, streamlining the process from development to deployment.
In 2023, we’ll see already-lean teams working more efficiently and with less risk as AI continues to be implemented throughout the development cycle.
“Specifically, AI-augmentation will help inform decision-making processes for devops teams by finding patterns and pointing out outliers, allowing applications to continuously ‘self-heal’ and freeing up time for teams to focus their brain power on the tasks that developers actually want to do and that are more strategically important to the organization.”
4. AI investments will move to fully-productized applications — Amr Awadallah, CEO, Vectara
There will be less investment within Fortune 500 organizations allocated to internal ML and data science teams to build solutions from the ground up. It will be replaced with investments in fully productized applications or platform interfaces to deliver the desired data analytic and customer experience outcomes in focus.
That’s because in the next five years, nearly every application will be powered by LLM-based neural network-powered data pipelines to help classify, enrich, interpret and serve.
But productization of neural network technology is one of the hardest tasks in the computer science field right now. It is an incredibly fast-moving space that without dedicated focus and exposure to many different types of data and use cases, it will be hard for internal-solution ML teams to excel at leveraging these technologies.
References
ai-trends-for-2023-industry-experts-and-chatgpt-ai-make-their-predictions/
AI is Changing Financial Services Delivery

AI is transforming the way businesses operate and invest, enabling them to identify patterns, make predictions, create rules, automate processes, and communicate more efficiently.
It is at the top of the agenda for financial services, as customers are becoming more informed and expect transparent as well as consistent and reliable services.
To generate value, banks and financial services organizations should be smart about choosing appropriate use cases and technologies. These use cases should outline what “measurable” success looks like both in the short and long term and should be assessed and prioritized based on the level of business impact and technological feasibility.
For example, classification type problems are commonly seen in banking, and AI-driven call center compliance automation is an example of using AI to classify high-risk calls for further review.
Mariette van Niekerk leads the Data Science & AI practice of Deloitte New Zealand’s Risk Advisory team, using a variety of machine learning / AI technologies to detect and manage fraud and operational risks.
She is a seasoned data scientist and project manager with a 12-year track record of delivering cross-industry operations research and artificial intelligence solutions. She recommends breaking the high-level plan for full roll-out down into smaller phases that deliver benefits early.
References
“How AI Is Shaping the Future of Financial Services.” Deloitte New Zealand, 18 May 2022
Challenges of Adopting AI in the Financial Industry
The use of AI in global banking is estimated to grow from a $41.1 billion business in 2018 to $300 billion by 2030. Traditional financial services companies have two objectives to fulfill with AI: speed, flexibility, and agility, and adhering to compliance standards and regulatory requirements.
However, big challenges remain in building responsible and ethical AI systems, and traditional financial institutions struggle to deploy in-depth AI capabilities to truly harness its full potential.


These include:
Data quality and weak core structures make it difficult for AI and ML systems to identify overlapping and conflicting entries.
Lack of support for AI-specific scale and volume and can even show biased results when written by developers with a biased mind.
Lack of standard processes and guidelines for AI in the financial domain.
The lack of talent, budget constraints.
Significant commitment toward AI investment. It is important to consider the context, use case, and type of AI model implemented to analyse the appropriate approach while collaborating or upscaling core tech systems.
The Economist’s research team found that 86% of Financial Service executives plan to increase AI-related investment over the next five years, with the strongest intent expressed by firms in the APAC and North American regions.
Businesses that scale with AI over time, will enjoy an unwavering focus on compliance, customer satisfaction, and retention.
References
AI Adoption Challenges in Traditional Financial Services Companies, 7 Mar. 2022
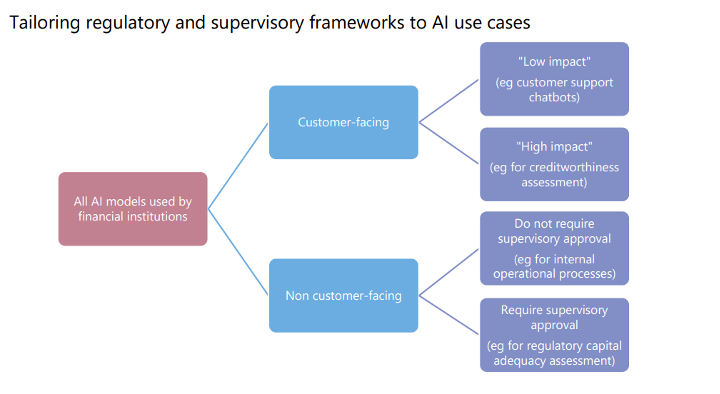
Role of Government and Regulatory Bodies in Financial Services AI
AI, including machine learning (ML), can improve the delivery of financial services as well as operational and risk management processes. Financial authorities are encouraging financial sector innovation and the use of new technologies.
As a result, sound regulatory frameworks are required to maximize benefits and minimize risks from these new technologies. There are AI governance frameworks or principles that apply across industries, and several financial authorities have begun developing similar frameworks for the financial sector.
These frameworks are based on general guiding principles such as dependability, accountability, transparency, fairness, and ethics. Financial regulators are under increasing pressure to provide more concrete, practical guidance.
Existing governance, risk management, and development and operation requirements for traditional models also apply.

{kind=link}
Businesses can benefit from this financial industry behemoth of JP Morgan. This section examines how one of the largest banks, JP Morgan Chase & Co. is using artificial intelligence to tackle a slew of mundane tasks.
The multinational is unwavering in its commitment to lowering costs, increasing operational efficiency, and
improving the client experience, and it has been an early adopter of disruptive technologies such as Blockchain.
They established a center of excellence within Intelligent Solutions in 2016 to investigate and implement a
growing number of use cases for machine learning applications across the organization.
They have a document review system, in which corporate lawyers analyse large amounts of data and sort and identify important pieces for litigation, which is one of the legal profession’s pain points.
According to a McKinsey & Co. study, nearly a quarter of lawyer work output can be automated. According to a study conducted by Frank Levy at MIT and Dana Remus at the University of North Carolina School of Law,
implementing machine learning could reduce lawyers’ billable hours by about 13%.
JP Morgan has also implemented a program called COiN, which uses unsupervised machine learning to automate the contract document review process. The primary technique employed is image recognition, and the algorithm can extract 150 relevant attributes from annual commercial credit agreements in seconds, as opposed to 360,000 person-hours for manual review.
COiN is proving to be more cost-effective, efficient, and error free, and the company is committed to its technology hubs for teams specializing in big data, robotics, and cloud infrastructure in order to find new revenue streams while reducing expenses and risks.
References:
“AI in Banking: A JP Morgan Case Study and Takeaway for Businesses.”
Conclusion
In conclusion, the current state of Artificial Intelligence in banking is rapidly evolving and has the potential to greatly improve the efficiency and accuracy of financial services. AI-powered solutions can help banks with tasks ranging from fraud detection to customer service and personalization.
However, the implementation of AI in the banking sector must be done with caution and proper regulations in place to ensure the safety and privacy of customers’ data and to prevent any potential biases in decision making.
As AI continues to mature, it is expected to bring significant benefits to the banking industry and its customers, and it is essential for banking executives to stay informed and proactive in incorporating AI technology into